Анализировать можно любые источники информации, например, новости в СМИ на определённую тему, учебники, архивные документы, исследовательские интервью, программы политических партий, посты в социальных сетях и т. д.
Ваша задача — читая тексты, найти в них интересные и релевантные теме вашего исследования детали. Иногда контент-анализ позволяет понимать и контекст, иногда — учитывает только количественные показатели.
Чем больше изучаемая база материалов, тем меньше чувствительность к контексту. Это иногда пытаются наверстать за счёт лингвистических методов, когда соотносят между собой слова, имея в виду их морфологию, части речи, связь друг с другом на уровне языка. Например, можно выявлять сходные конструкции в статьях Википедии и делать на основе этого открытия об их содержании, даже не зная языка. Это сделали в своём исследовании Борис Орехов и Кирилл Решетников и обнаружили гонку в национальных Википедиях: горные и луговые марийцы состязались в том, у кого больше вики-раздел на национальном языке. Но мы будем говорить о более традиционном для социальных наук контент-анализе на примерах анализа СМИ.
Контент-анализ позволяет учитывать, в частности:
- упоминание определённых элементов текста и частоту их упоминания;
- обобщённые эмоциональные оценки (позитивный/негативный);
- структуру текста (деление на предложения/абзацы, смысловое содержание — что именно упоминается, а что, возможно, нет);
- динамику развития ситуаций (например, как изменяется освещение разными СМИ одного и того же события с течением времени).
Примеры исследовательских вопросов для К-А:
- Как соотносятся, чем отличаются друг от друга материалы офлайн-газет и онлайн-СМИ или блогов при освещении темы мигрантов в Москве?
- Как партия «Feminist Initiative» в Швеции включает различные социальные группы в проект феминистской политики? Что или кто конструируется как антагонист этой политики? (по материалам исследования)
- Есть ли связь между половой принадлежностью пользователя MySpace и типами его самопрезентации (например, количеством текста в разделе «About me», в различных категориях «Interest», в невербальном поведении на фото в профиле)? (по материалам исследования)
С чего начинается анализ? В первую очередь, с подготовки базы данных и принятия решения о том, как мы будем её анализировать. Мы составляем план и собираем в единую систему то, что будем искать в источниках.
Как подготовить базу данных?
- Сохранить все материалы в едином формате — особенно если это важно при работе с онлайн-контентом. Лучше всего скачать материалы так, чтобы не возвращаться к оригинальному сайту — чтобы нужная вам информация не потерялась из-за обновлений сайта. Единообразие должно заключаться в том, какие элементы текстов будут у вас в базах. Например, это могут быть полные тексты статей, с заголовками и лидами. Наконец, если вы, скажем, взялись за инстаграм, стоит определить: будете ли вы анализировать только картинки, или также подписи и хэштеги. Принимать такие решения всегда непросто, но нужно ориентироваться на задачу: сможете вы с помощью того или иного инструмента её решить или нет.
- Понять, насколько большим будет ваш материал. Это поможет вам определиться с инструментом, увидеть, сможете вы его обработать вашу базу вручную или понадобятся компьютерные методы.
- В любом случае, вам скорее всего пригодится таблица (для перечисления и структуризации элементов анализа) и текстовые документы. Нужно принять решение, будете вы работать в Office/Open Office или онлайновых редакторах вроде Google Docs. Последние удобны тем, что в них удобно работать коллективно. Но в них меньше возможности форматирования, чем в офлайновых офисных пакетах.
Затем нужно выделить категории анализа.
Например, основываясь на нашем исследовательском вопросе, можно выделить следующие категории:
- упоминание государств как действующих лиц (акторов);
- упоминание других акторов;
- упоминание терминов, связанных с инфраструктурой интернета;
- характеристика возможных действий акторов с интернетом.
Далее выделим единицы анализа.
В зависимости от категории, единицы анализа могут быть разными, например:
- термины, понятия, обозначения;
- темы и инфоповоды, например: события в период блокировки Telegram;
- имена значимых персон (или групп);
- названия государств, компаний, организаций, территорий, социальных и культурных объектов;
- общественные события, факты, социальные ситуации;
- подтекст и оценка (Что пытаются донести авторы новостей и материалов до читателей? Имеется ли ещё что-либо кроме информирования, например, позитивная или негативная оценка явлений или действий значимых персон?).
Можно не задавать единицы анализа заранее, а определить их в процессе работы с текстом. В таком случае вы можете отмечать те части в тексте, которые кажутся вам подходящими и релевантными интересующей вас теме. Это может быть, например:
- то, что неоднократно повторяется в тексте;
- то, что обращает на себя внимание, наводит на мысль, кажется удивительным;
- то, что информант (или автор текста) отмечает как важное;
- то, с чем вы уже сталкивались в ходе изучения вашей темы (в том числе связанное с теорией, определениями).
Единицы анализа иногда нужно не только найти, но и сосчитать. Для этого вводим единицу счёта. анализа должны быть легко обнаружимы. А одна категория не может характеризоваться одной единицей анализа: их должно быть столько, чтобы из них можно было выбирать.
Единицы анализа важно не только найти, но и сосчитать. Для этого вводим единицу счёта.
В каких случаях единицей счёта может стать большой объём текста (например, абзац или статья)? Чаще всего, в ситуациях, когда вам нужно дать какую-то характеристику этому тексту (определить тип материала, эмоциональную окраску, отметить наличие или отсутствие каких-либо элементов и т. п.).
Для удобства в дальнейшей работе единицам анализа можно присвоить свои коды — числовые или буквенные. Это может выглядеть так:
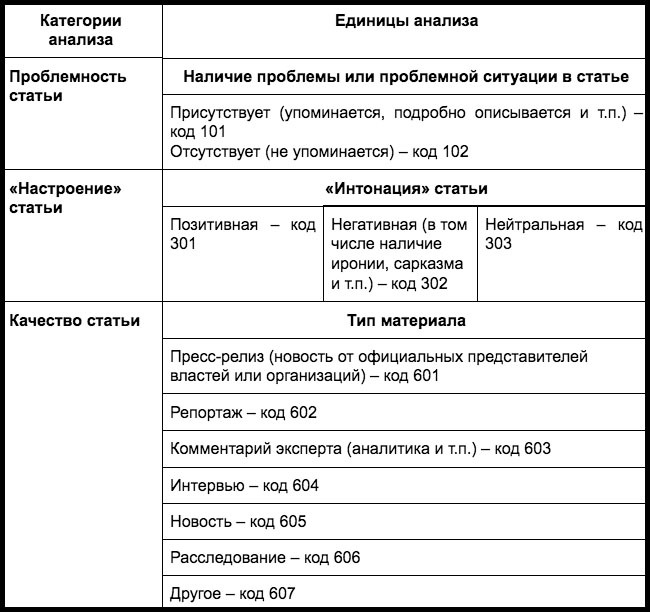
Подготовка
Прежде чем приступать к кодировке всего массива данных, нужно сделать пилотаж — пробную кодировку небольшого количества текстов. Так вы сможете проверить, не упустили ли вы чего-либо при составлении системы анализа — возможно, ваши категории или единицы анализа стоит дополнить. Еще делают так: два кодировщика кодируют один и тот же массив и потом оценивается процент совпадений. Обычно в публикациях в части методологии даже указывают этот процент, например 80%.
Если вы кодируете вручную, проще всего составить таблицу, где в «шапке» столбцов будут перечислены все ваши единицы анализа, а строки будут соответствовать источникам (статьям, главам, параграфам и т. п.).
Но можно делать это и не вручную.
Какие программы могут пригодиться вам для контент-анализа?
- Excel (а также родственные ей Numbers и Spreadsheets) — отличная базовая программа. С её помощью можно и кодировать, и анализировать полученные данные.
- Обрабатывать данные можно в статистических программах, например, в SPSS.
- Также можно пользоваться различными программами, созданными специально. Например: QDA Miner, CATPAC, Yoshikoder, TextAnalyst. Здесь можно почитать про них подробнее: http://content-analysis.ru/

Для наглядности разными цветами подчёркнуты единицы анализа разных категорий: упоминание государств, упоминание других акторов, интернет-термины, действия акторов по отношению к интернету.

Возможны два способа создания системы анализа (кодов и категорий):
- в случае bottom-up кодирования вы находите коды и категории, релевантные вашим исследовательским задачам, формируете их список в ходе анализа текстов. Система анализа не задана заранее, а создаётся и дополняется, когда вы изучаете текст;
- в случае top-down кодирования вы заранее формируете список кодов и категорий и сразу применяете его к текстам. Систему анализа также можно дополнять в ходе исследования, но она существует заранее.
В ходе исследования вы занимаетесь поиском и изучением определённых концептов.
Концепт «второго порядка» — это категория: обобщающее понятие, включающее в себя несколько кодов по одной тематике.
Как соотносятся коды и категории? Коды отражают возможные варианты проявления какой-либо категории в анализируемом тексте. Категории, таким образом, состоят из кодов. В похожем отношении находятся категории и единицы анализа в количественном анализе.
Например: категория — политические взгляды, коды — «либеральные», «консервативные» и т. п.
анализ полученных данных
Можно сравнить данные количественно:
- сколько раз упоминается объект?
- какова динамика? например, увеличивается ли частота упоминаний со временем?
- связаны ли упоминания объектов? (например, встречаются ли вместе слова интернет и зависимость?)
- есть ли решительные несовпадения между упоминаниями разных объектов? например, когда в один период времени объекты встречаются всегда вместе, а в другой — нет?
Если идти глубже, можно понять общие закономерности высказываний: какие элементы текста используются вместе, а какие — никогда, какие имена и оценочные высказывания связаны друг с другом в материалах, которые вы изучаете.
- Media profiles of living and dead public intellectuals on the Internet and in traditional media (Danowski & Park, 2009)
- Campaign information as unmediated messages on candidate web sites(Druckman et al., 2010; Druckman, Kifer, & Parkin, 2010)
- New forum comments on TV and newspaper web sites (Hoffman, 2015)
- Nonverbal displays of self-presentation on MySpace (Kane et al., 2009)
- Facebook pages dedicated to moms (Kaufmann & Buckner, 2014)
- Filimonov, K., & Svensson, J. (2016). (re) Articulating Feminism. Nordicom Review, 37(2), 51-66. URL: http://www.nordicom.gu.se/sites/default/files/kapitel-pdf/10.1515_nor-2016-0017.pdf
- Filimonov, K., Russmann, U., & Svensson, J. (2016). Picturing the party: Instagram and party campaigning in the 2014 Swedish elections. Social Media+ Society, 2(3). URL: http://journals.sagepub.com/doi/pdf/10.1177/2056305116662179
- Paulussen, S., & D'heer, E. (2013). Using citizens for community journalism: Findings from a hyperlocal media project. Journalism Practice, 7(5), 588-603.
- Neuendorf, Kimberly A. The content analysis guidebook / Kimberly A. Neuendorf, Cleveland State University, USA. Description: Los Angeles : SAGE, [2017]
- J. Hunsinger, M. Allen, & L. Klastrup (Eds.), The International Handbook of InternetResearch. Springer Verlag. / Web Content Analysis: Expanding the Paradigm Content Analysis of Online Discussion in an Applied Educational Psychology / Noriko Hara, Curtis J. Bonk, & Charoula Angeli, November 20, 1998
- Семёнова А.В., Корсунская М.В. Контент-анализ СМИ: проблемы и опыт применения / Под ред. В.А. Мансурова. – М.: Институт социологии РАН, 2010..
клуб любителей интернета и общества
онлайн-школа интернет-исследований
текст тьюториала: Александра Гончарова и Александра Кейдия
редактура и вёрстка: Маша Мурадова
иллюстрации: Алиса Рангаева
щёлк-щёлк: Лёня Юлдашев